本篇為論文 Unveiling Selection Biases: Exploring Order and Token Sensitivity in Large Language Models 的白話文介紹,欲瞭解更多細節建議閱讀原論文。
 我用 GPT-4o 產的封面圖,雖然不盡完美破圖明顯,但僅以紀錄 2024 年 6 月 AI 技術的極限
我用 GPT-4o 產的封面圖,雖然不盡完美破圖明顯,但僅以紀錄 2024 年 6 月 AI 技術的極限
隨著大型語言模型 (Large language model,以下簡稱 LLM) 的蓬勃發展,人們開始使用如 ChatGPT、Gemini、Claude、Perplexity 做各種任務,其中,讓 LLM 做「選擇」是一個常見的情境,包含但不限於:
- 選擇題 (Multiple Choice Questions)
不論你升高中考的是基測或會考,升大學考的是學測/統測/指考/分科,身為在台灣求學的我們再熟悉不過的情境,題目給定一段文字,並給予 4–5 個選項,作答者需要從中選出正確的答案。
延伸閱讀:地表最強AI「ChatGPT」考指考 能上台大醫科嗎?
- 扮演評分者 (LLM as Evaluator/Judger)
有些應用希望透過 LLM 強大的能力來取代評分者,以降低人力的耗用。例如:給一篇作文分數。如果是「選擇」的情境,將會變成給定 A 、B 兩篇作文,請模型挑出比較好的那篇。
然而,許多研究發現,LLM 在做「選擇」時會有偏見,包含對於選項符號和選項順序,就好比,以前考試不會的都寫 C 一樣 😂
對於僅想利用 LLM 做點事的我們,這樣的偏見或者說現象,可能會對結果有所影響,因此我想深入的探討這個問題,並試著提出一些解法,希望讓更多像我一樣會用 LLM 做事的人有所幫助。
觀察 LLM 對於選項符號和順序的敏感度
讓我們用去年 112 年國中會考社會科的題目來當例子吧:
《周成過臺灣》是著名的民間傳說,其時代背景符合史實。故事描述周成拋下故鄉泉州的妻兒,獨自來臺經商。適逢淡水、雞籠開港通商,周成在大稻埕從事新興商品出口而致富。後來周成移情別戀,謀殺了來臺灣探視的妻子,最終受到報應而死。根據上述內容,周成最有可能從事下列何種商品的貿易? (A) 茶葉 (B) 鹿皮 (C) 蔗糖 (D) 鴉片
我們想要探索 LLM 在題幹不變的情況下,對於選項符號和順序的敏感度,透過調整以下三個設定,來觀察 LLM 結果的變化。
正序 (forward) 時選項和原題目相同,而我們根據不同設定,來調整倒序 (backward) 時選項。
1. 符號敏感度 (Token Sensitivity)
符號對於 LLM 決策的影響
倒序 (backward) 時,選項為:
(D) 茶葉 (C) 鹿皮 (B) 蔗糖 (A) 鴉片
直觀來說,觀察選項順序不變的狀況下,搭配不同的符號是否會影響 LLM 的決策。像例子中,假設正序的狀況下 LLM 選擇了茶葉,我們好奇如果茶葉從 (A) 變為 (D),LLM 回答的結果是否改變。
2. 順序敏感度 (Order Sensitivity)
順序對於 LLM 決策的影響
倒序 (backward) 時,選項為:
(D) 鴉片 (C) 蔗糖 (B) 鹿皮 (A) 茶葉
想法類似,但在順序敏感度的設定下,我們改成調整選項的順序,但不改變其對應的符號。舉例來說,茶葉在正序和倒序狀況皆為 (A) 選項,但位置卻從第一個選項變成第四個選項。
3. 綜合敏感度 (Both Sensitivity)
符號和順序對於 LLM 決策的影響
倒序 (backward) 時,選項為:
(A) 鴉片 (B) 蔗糖 (C) 鹿皮 (D) 茶葉
綜合上面兩種設定,如果同時改變符號和順序,對 LLM 的影響又為何?舉例來說,茶葉從 (A) 變為 (D) 之外,也從第一個選項變成第四個選項。
評估敏感度的方式
為了計算 LLM 對於符號和順序的敏感度,我們訂了搖擺率 (Fluctuation Rate) 這個指標,代表著 LLM 在正序和倒序的狀況下,做出不同的決策。
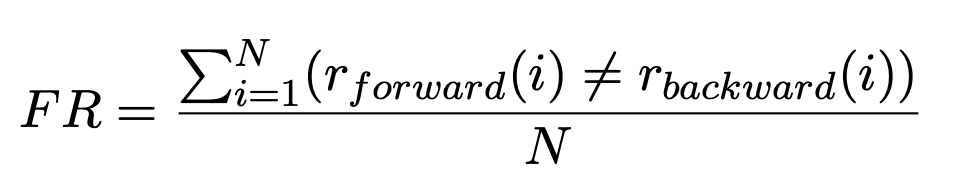
舉例來說,上面的例子,在綜合敏感度的設定下,正序時 LLM 選了 (C) 蔗糖,但倒序時卻選了 (D) 茶葉,那我們會說 LLM 在這題是搖擺的。搖擺率即代表總共 N 題中,LLM 做出不同決策的比率。
特別注意,搖擺率和正確率 (Accuracy) 並不相關,這裏我們在乎的是 LLM 因為選項符號、順序改變對於決策的影響,就好比,假設有個題目問澳洲首都是哪裡,而你心中以為是雪梨,此時雪梨不論是在 (A) (B) (C) (D) 哪一個選項你應該都會選(即使正確答案其實是堪培拉)。
實驗結果和觀察
我們用了六個不同的資料集,包含 ARC-Challenge、HellaSwag、MMLU、Winogrande、MathQA、OpenBookQA,涵蓋了各種類型的問題,舉凡人類常識問答、數理問題 (STEM)、社會科學、人文、醫療、財金等。
使用的模型涵蓋了三個不同系列的模型,Google 的 PaLM2 和 Gemini Pro 1.0,OpenAI 的 ChatGPT 3.5 (GPT4 太貴了QQ)、Meta 的 LLaMA 2 三個不同的模型大小 (7B、13B、70B)。
下表中 T、O、B 分別代表符號敏感度 (T)、順序敏感度 (O)、綜合敏感度 (B),Acc 代表正確率,Fluct 則代表我們定義的搖擺率。
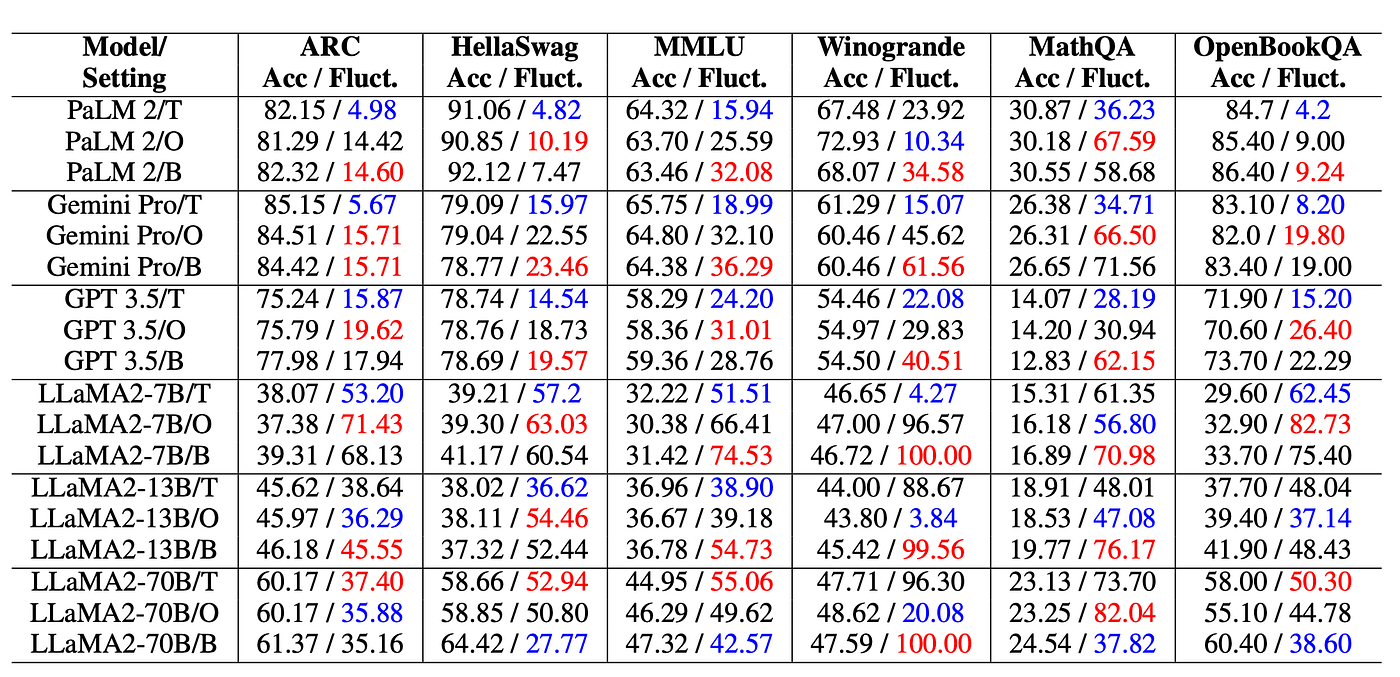
一個有趣的發現
從上表中,我們觀察到題目的難度似乎和搖擺率有些關係,為了驗證這件事,我們使用了 MMLU 來觀察這個現象,並試著把正確率和搖擺率畫成散佈圖,意外發現兩者確實存在著趨勢。
備註:MMLU 這個資料集涵蓋了 57 個不同科目的考題,像是高中數學、大學物理、總體經濟學、個體經濟學、行銷學、國際關係等。
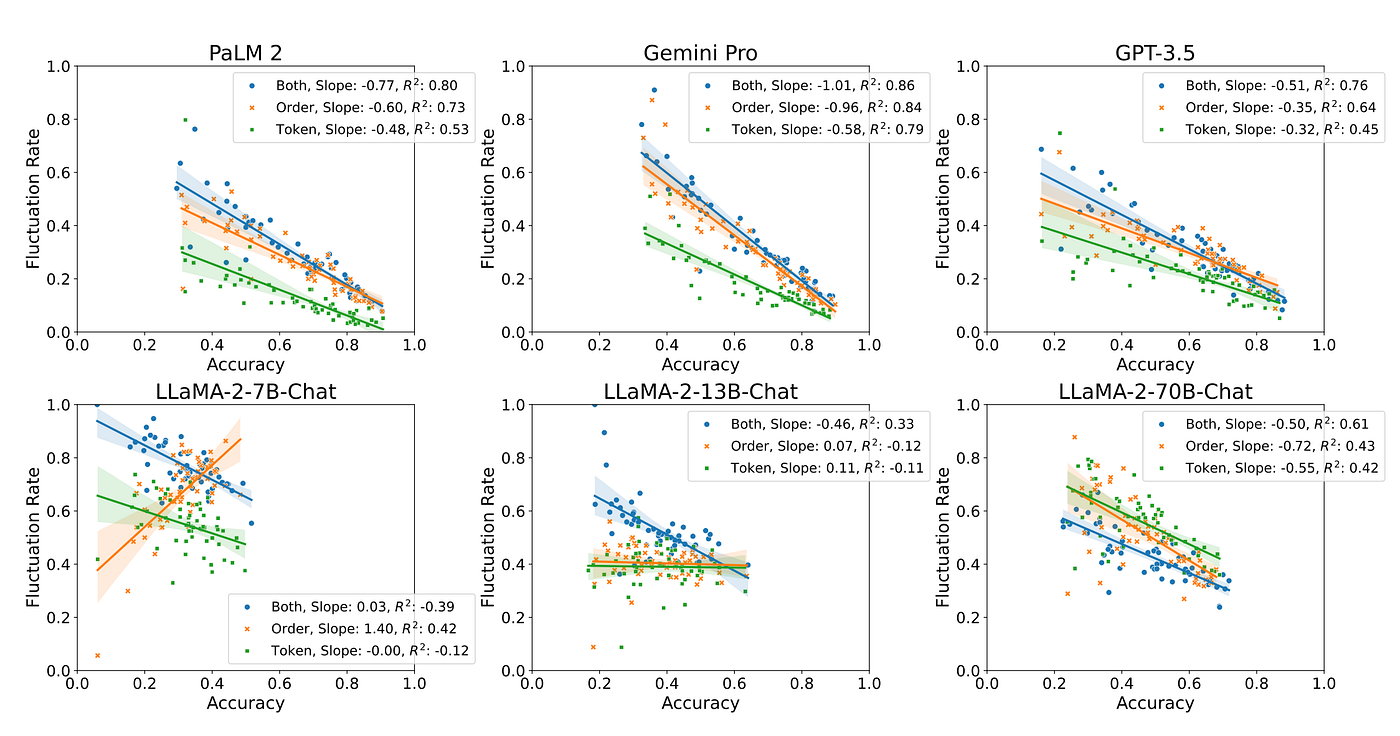
從圖中我們可以發現,正確率越高(即題目越簡單),搖擺率相對越低(不容易被選項符號、順序影響),在 PaLM2、Gemini、GPT3.5、LLaMA2 70B 皆有這個現象,這和人類的行為也雷同,我們在作答時,如果題目很難,四個選項都看不懂,我們也傾向亂猜,很難選到同一個答案。
另一個有趣的現象是,在模型能力明顯不足時,猜測因為其對題目的掌握度不高,因此正確率越高,搖擺率越低這個趨勢並不存在,但當模型能力逐漸增加,這個現象就會慢慢出現,試著觀察 LLaMA 2 模型在 7B、13B、70B 的結果。
Conclusion
在這篇文章,我們白話文說明了 Unveiling Selection Biases: Exploring Order and Token Sensitivity in Large Language Models 這篇論文的前半部分,讓大家了解 LLM 對於選項符號和順序是會有偏差 (Bias) 的,論文的下半部有提供了減緩這些偏差的方式,讓我們留到下篇再與大家分享(等不及的建議直接去看原論文)。