本篇為論文 Unveiling Selection Biases: Exploring Order and Token Sensitivity in Large Language Models 的白話文介紹(下篇),建議先閱讀上篇。
距離上篇發布已經過了將近兩年,不小心富奸了。在這段時間裡,LLM 的世界已經翻了好幾輪,但這篇論文探討的偏差問題依然存在,所以這篇下篇應該還沒有過期(吧)。
前情提要
在上篇中,我們介紹了 LLM 在做選擇題時存在的偏見,包含對選項符號 (Token Sensitivity) 和選項順序 (Order Sensitivity) 的敏感度,並定義了搖擺率 (Fluctuation Rate) 來量化這些偏差。我們也發現了一個有趣的現象:題目越難,LLM 越容易搖擺,和人類考試的行為非常類似。
但光是知道問題存在還不夠,我們更想知道的是,有沒有辦法減緩這些偏差?
這篇文章將介紹我們提出的三種方法,分別針對不同的使用情境。
從開源到 API:你能掌握多少模型資訊?
在講解法之前,我們得先搞清楚你是怎麼使用 LLM 的,因為不同的使用方式,決定了你能拿到多少模型的內部資訊,也決定了你能用什麼方法來緩解偏差。
-
White-Box(完全透明):你把開源模型(如 LLaMA、Mistral)下載到自己的機器上跑,模型的所有資訊都攤在你面前,每個 token 的完整機率分佈、模型權重、中間層的 hidden states,想看什麼就看什麼。
-
Gray-Box(部分透明):你透過 API 呼叫模型,雖然看不到模型內部,但 API 可以回傳 token 的機率值。例如 OpenAI 的 GPT-4o、GPT-5.4,以及 Anthropic 的 Claude Sonnet 4.6 和 Claude Opus 4.6 都支援
logprobs參數,讓你知道模型選 (A) 的機率是 60%、選 (B) 是 25%⋯⋯等資訊。 -
Black-Box(完全不透明):你只拿到模型最終的答案,例如「答案是 (A)」,但不知道它有多猶豫。透過 ChatGPT、Gemini 網頁版使用時通常屬於這種情境。
在我們的論文中,針對 Gray-Box 提出了兩種方法,針對 Black-Box 提出了一種方法。以下我們聚焦在多數人比較常遇到的 Gray-Box 和 Black-Box 情境。
方法一:Probability Weighting(機率加權法)
這是我們針對 Gray-Box 情境提出的第一種方法,核心想法很直覺:既然正序和倒序會讓模型產生不同的偏差,那我們就把兩次的結果「合在一起看」,讓偏差互相抵銷。
讓我們回到上篇那道會考題。假設我們用綜合敏感度的設定,正序和倒序分別是:
| 正序 | 倒序 | |
|---|---|---|
| (A) | 茶葉 | 鴉片 |
| (B) | 鹿皮 | 蔗糖 |
| (C) | 蔗糖 | 鹿皮 |
| (D) | 鴉片 | 茶葉 |
模型回答兩次後,我們從 API 拿到每個選項符號的機率值:
| 選項符號 | 正序機率 | 倒序機率 |
|---|---|---|
| (A) | 0.50 | 0.40 |
| (B) | 0.10 | 0.15 |
| (C) | 0.25 | 0.10 |
| (D) | 0.15 | 0.35 |
注意正序的 (A) 是茶葉,但倒序的 (A) 是鴉片,符號一樣,內容不同。所以我們不能直接比符號,要追蹤的是選項內容。因此,我們把同一個選項內容在兩次出現時的機率相乘:
| 選項內容 | 正序(符號 → 機率) | 倒序(符號 → 機率) | 加權機率 |
|---|---|---|---|
| 茶葉 | (A) → 0.50 | (D) → 0.35 | 0.50 × 0.35 = 0.175 |
| 鹿皮 | (B) → 0.10 | (C) → 0.10 | 0.10 × 0.10 = 0.010 |
| 蔗糖 | (C) → 0.25 | (B) → 0.15 | 0.25 × 0.15 = 0.038 |
| 鴉片 | (D) → 0.15 | (A) → 0.40 | 0.15 × 0.40 = 0.060 |
加權機率最高的是茶葉 (0.175),所以最終答案選茶葉,也就是正確答案 🎉
注意到了嗎?倒序時鴉片靠著 (A) 的位置優勢拿到了 0.40 的高機率,但正序時它只有 0.15,相乘之後就被壓下去了。這就是加權法的精髓:讓兩次的偏差互相抵銷,真正有實力的選項才能勝出。
以 GPT-3.5 的實驗結果來看,這個方法在六個資料集上平均提升了 +2.9% 的正確率,而且只需要額外一次 API 呼叫,相比過往方法大多透過排列組合窮舉所有選項順序再投票決定答案,成本降低許多。
方法二:Probability Calibration(機率校正法)
加權法雖然有效且成本不高,但畢竟還是需要對同一個問題問兩次。如果我們還是只想問一次但又想減緩偏差呢?或許先搞清楚模型的「偏好」長什麼樣子,再拿來修正它的答案,這就是校正法的概念。
什麼意思呢?回到上篇的觀察,大部分 LLM 都有偏好特定選項符號的傾向,例如很多模型特別喜歡選 (B) 或 (C)。如果我們能事先知道這個偏好的分佈,就能在模型回答時「扣掉」這部分的偏差。
具體做法分兩步:
第一步:用驗證集算出模型的偏好分佈。 我們讓模型在一組驗證資料上作答,統計它選 (A)、(B)、(C)、(D) 各佔多少比例。假設結果是:
| 選項符號 | 模型選擇比例 |
|---|---|
| (A) | 18% |
| (B) | 29% |
| (C) | 30% |
| (D) | 23% |
正常來說,如果沒有偏差,四個選項應該各約 25%。但模型明顯偏好 (B) 和 (C)。
第二步:用偏好分佈來校正每一題的機率。 拿模型原始的機率除以對應的偏好比例,就像是在說:「你本來就愛選 (C),所以你給 (C) 的高機率要打個折扣。」換句話說,如果模型本來就很偏好 (C),那它就要對 (C) 展現更高的信心,我們才能相信它真的覺得 (C) 是對的。
繼續用那道會考題舉例,假設正序時模型給的機率是:
| 選項 | 原始機率 | 偏好比例 | 校正後機率 |
|---|---|---|---|
| (A) 茶葉 | 0.50 | 0.18 | 0.50 ÷ 0.18 = 2.78 |
| (B) 鹿皮 | 0.10 | 0.29 | 0.10 ÷ 0.29 = 0.34 |
| (C) 蔗糖 | 0.25 | 0.30 | 0.25 ÷ 0.30 = 0.83 |
| (D) 鴉片 | 0.15 | 0.23 | 0.15 ÷ 0.23 = 0.65 |
校正後,茶葉依然是最高的,而且差距拉得更大了,因為它的高機率不是靠偏好灌出來的。
這個方法的好處是只需要一次 API 呼叫(不需要問正序和倒序),但前提是你需要先跑一組驗證集來建立偏好分佈(不需要太多,大約 50 到 100 題即可)。在 GPT-3.5 上,校正法在 MathQA 上帶來了高達 +9.72% 的提升。
Gray-Box 兩種方法的比較
那加權法和校正法放在一起比,誰表現比較好?以下是 GPT-3.5 在六個資料集上的結果:

加權法在多數任務上穩定提升;校正法則在 MathQA(+9.72%)和 Winogrande(+4.74%)上更為突出。值得注意的是,這兩個資料集的選項數量都不是標準的四個(分別是 5 個和 2 個),暗示選項數量可能影響方法的效果。
方法三:Two-Hop Strategy(兩步驟策略)
前面兩種方法都需要拿到 token 機率,但如果你是透過網頁版使用,或是 API 沒有提供 logprobs 呢?這時候就需要 Black-Box 的解法了。
兩步驟策略的想法很直觀:既然我拿不到機率,那我就想辦法避開模型最偏好的那個選項符號。
一樣分兩步:
第一步:找出模型最偏愛的選項符號。 跟校正法一樣,先用驗證集統計模型的選項偏好分佈。假設我們發現模型最愛選 (C),佔了 30%。
第二步:兩步驟決策。 對每道題目,先讓模型回答一次(正序)。如果答案不是最偏的符號 (C),就直接採用,因為模型在「沒有被偏好推著走」的情況下做出的選擇比較可信。但如果答案剛好是最偏的符號 (C),我們就懷疑這個答案可能是偏差造成的,這時再問一次(倒序),改採用倒序的答案。
用那道會考題來說明。假設模型最偏愛 (C),正序時模型選了 (A) 茶葉,因為 (A) 不是最偏的符號,我們就直接採用,答案是茶葉,正確 🎉。換一個情境,假設正序時模型選了 (C) 蔗糖,因為 (C) 正好是最偏的符號,我們就改看倒序的答案。倒序時模型選了 (D) 茶葉,最終答案一樣是茶葉 🎉。
這個方法的精妙之處在於它不需要任何機率資訊,最多只需要兩次問答,就能減緩模型最大的盲點。實驗結果顯示,PaLM 2 和 Gemini Pro 在六個資料集中有五個獲得了提升,GPT-3.5 也在四個資料集上有改善。
不過它也有限制,在 Winogrande 這個只有兩個選項的資料集上,所有模型的表現反而下降了。我們猜測當選項太少時,偏好分佈的假設可能不太成立。
以下是兩步驟策略在不同模型上的完整結果:
較強的模型(PaLM 2、Gemini Pro)受益最大,六個任務中有五個獲得提升。GPT-3.5 也在四個任務上改善。但 LLaMA 2 系列則是喜憂參半,在一半的任務上有效,另一半則沒有明顯變化。
有趣觀察:哪些科目改善最大?
我們特別用 MMLU 這個涵蓋 57 個科目的資料集做了細部分析,想看看不同學科受益的程度有沒有差異。
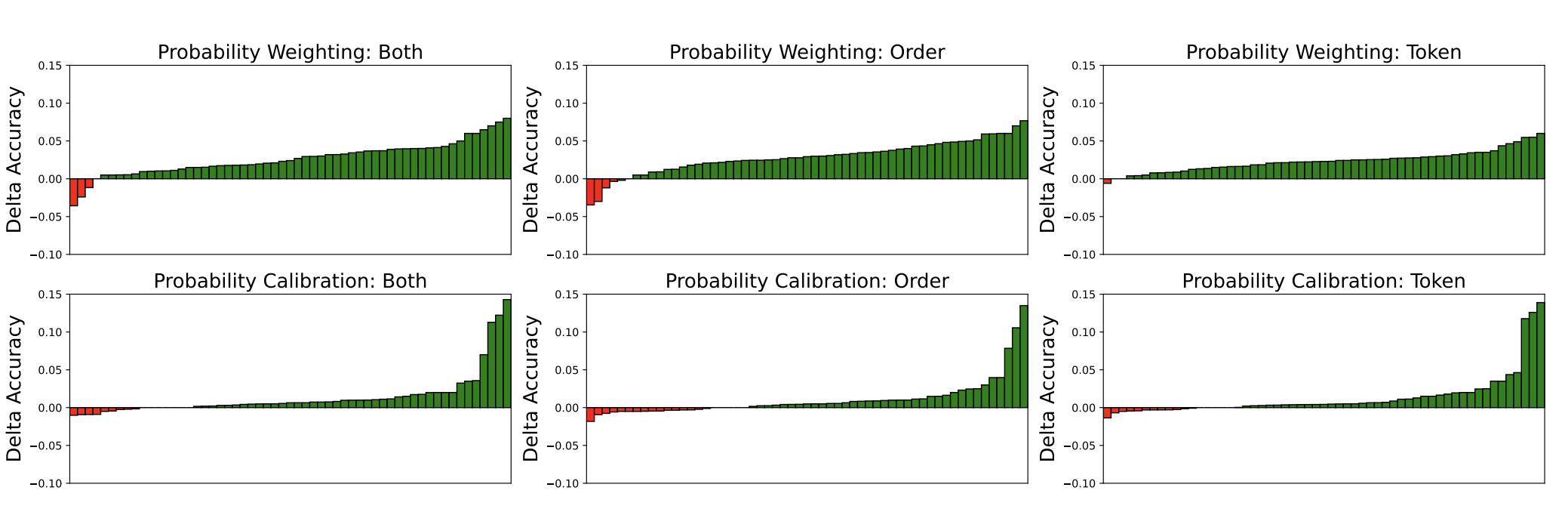
結果發現,STEM 類科目的改善最為顯著。以 GPT-3.5 的校正法為例,進步最大的前幾名是:
| 科目 | 正確率提升 |
|---|---|
| 小學數學 (Elementary Mathematics) | +14.29% |
| 高中數學 (High School Mathematics) | +12.22% |
| 大學物理 (College Physics) | +11.27% |
| 大學化學 (College Chemistry) | +7.00% |
相較之下,少數記憶類的任務反而出現了小幅下降,像是機器學習 (-3.57%)、商業倫理 (-3.46%)。
為什麼 STEM 進步最大?一個可能是數理題有明確的正確答案,模型只是因為偏差選錯了符號,一旦偏差被校正,正確答案就浮出來了。另一個可能是這些科目的題目本身較難,模型更容易搖擺(呼應上篇的觀察),校正偏差的空間也更大。相對地,記憶類任務的改善幅度較小,甚至出現小幅下降。
整體來看,加權法大約只有 6% 的科目出現下降,校正法則有約 22% 的科目下降。換句話說,加權法更「安全」,而校正法的爆發力更強但穩定性稍差。
結語
在上下兩篇文章中,上篇我們發現 LLM 做選擇題時會因為選項的符號和順序產生偏差,並用搖擺率來量化這個現象。下篇我們則提出了三種解法:Gray-Box 情境下可以用加權法或校正法,Black-Box 情境下可以用兩步驟策略。
整體來看,如果你能拿到機率,優先用加權法,穩定且成本低,只需要多一次 API 呼叫。如果你的任務是 STEM 類或選項數量不是標準的 4 個,可以試試校正法,可能會有意外驚喜。如果你只有 Black-Box,那兩步驟策略是你唯一的選擇,對較強的模型效果不錯。
如果你在工作中會用 LLM 來做選擇或評分,希望這篇文章能讓你多一層意識:模型的答案可能不只取決於題目本身,也取決於你怎麼排列選項。好消息是,這個問題是可以被緩解的。
完整論文請參考:Unveiling Selection Biases: Exploring Order and Token Sensitivity in Large Language Models,程式碼開源在 GitHub。